

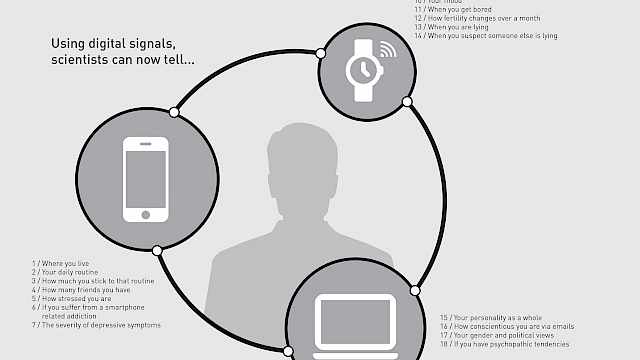




Biometrics are becoming increasingly prevalent in our everyday lives. They have moved from something that belonged to the realms of science fiction to a technology that many of us interact with several times a day.
One of the most common ways we use biometrics is to secure our personal devices with our fingerprint or face, but biometrics also have a wide range of other uses from managing physical access through to immigration controls.
Broadly speaking, biometrics fall into two categories: physical and behavioural.
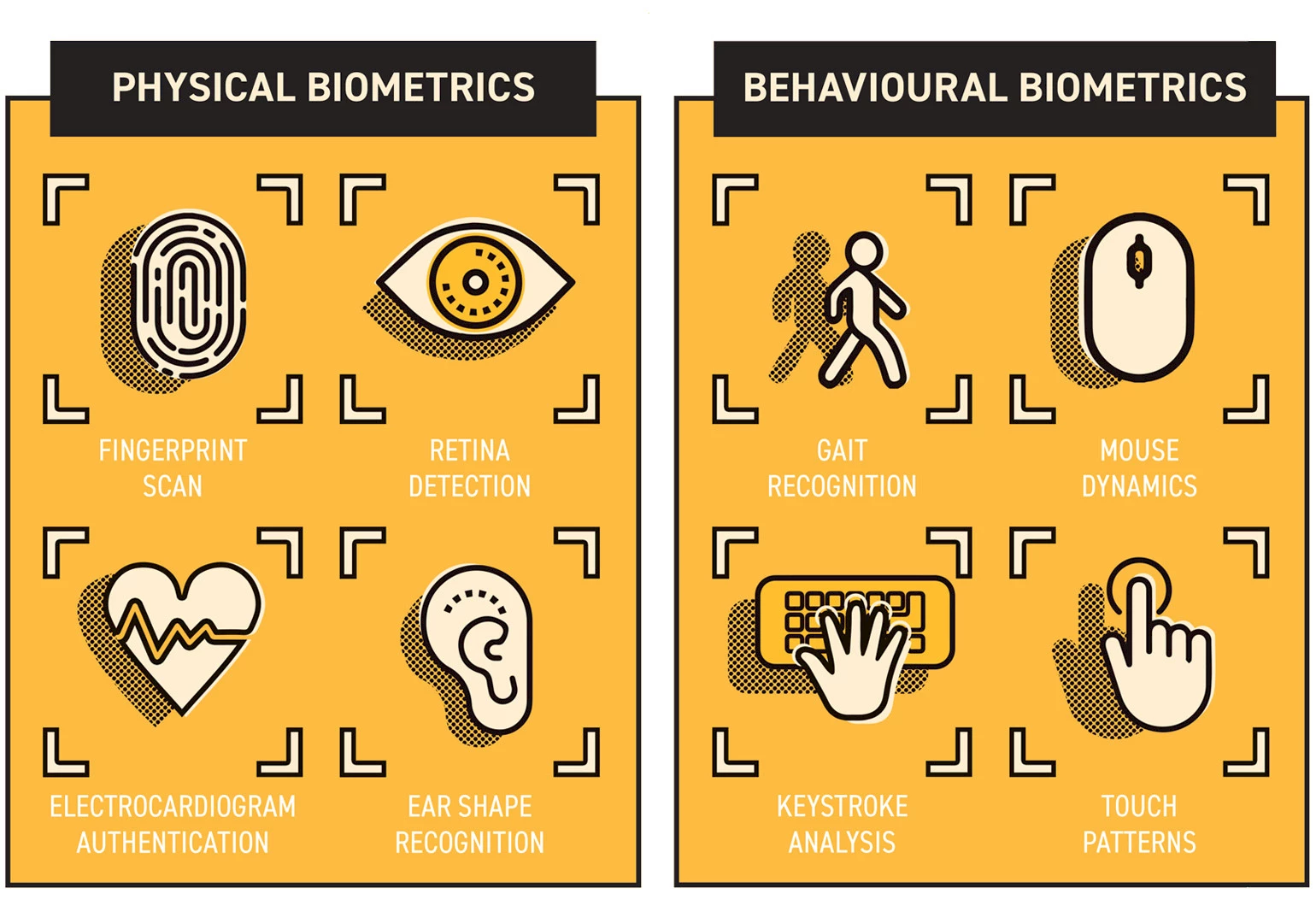
Physical biometrics
Physical biometrics tend to be what people think of when the term ‘biometrics’ is mentioned. They are essentially measurable characteristics of your body that can be used to confirm the identity of an individual. They can range from the commonly used methods, e.g. fingerprint scan and facial recognition, through to more novel methods like ear shape recognition or electrocardiogram authentication.
Behavioural biometrics
Behavioural biometrics, on the other hand, measure how we perform specific tasks, e.g. from how we interact with a computer (using a mouse or keyboard) to the way we walk.
Identifying individuals based on their behaviours is not a recent idea and a similar method was used to help identify Morse code operators during WW2. The technology can be used to authenticate an individual to use a system or to continuously confirm the identity of the authenticated user. This could take the form of monitoring a user’s typing patterns or mouse movements as they use a website and comparing this to their ‘normal’ behaviour to highlight any significant deviations.
Keystroke dynamics
Keystroke dynamics is the analysis of how individuals type and can be used to draw identifying characteristics about an anonymous end user. The typing behaviours displayed by an individual can be as uniquely identifiable as their handwriting or signature. There has been significant research into analysing the typing rhythms and also the cadence of users to identify them. Similarly, these techniques have been used to derive physical attributes and demographic information – known as soft biometrics – about keyboard users, such as their hand size, handedness and gender.
My research focuses on how typing patterns can be used to provide identity cues for anonymous individuals. The aim of the project is to evolve soft biometrics to provide more focused identity information about an individual, such as their name or native language.
The typing behaviours displayed by an individual can be as uniquely identifiable as their handwriting or signature
The work is based on the concept of motor learning, which is the process of acquiring or developing skills based on experience – as our familiarity with a task increases, it becomes increasingly automatic and requires less conscious thought. A good example of this is learning to drive: When we first sit in the driver’s seat, even changing gear is a monumental task! But, as our experience increases, the various tasks associated with driving become less and less demanding. The same principle applies to how we use a keyboard; the things we type regularly, like our PIN or name, become more automatic and invariably quicker than other key combinations.
Bigrams
My approach divides words into pairs of letters, known as bigrams. As an example, it would be anticipated that an individual called ‘John’ would have a greater familiarity with the n-grams ‘jo’, ‘oh’ and ‘hn’, and so would type these groupings more quickly.

I record users’ keystrokes and rank the speed they type each bigram to develop a ‘normal’ profile for that user. The bigrams that are highly ranked are those that the user is most familiar with. Some of these are a facet of their native language (‘th’ and ‘er’ in English) and some are related to other identifiable information.
Filtering out the bigrams that are common to a user’s native language has two benefits:
- It reduces the search space when predicting a user’s name
- It provides a model to identify a user’s native language based on this information.
My initial experiments have been able to correctly predict the presence of a bigram in an anonymous user’s name 71% of the time. The overlapping nature of bigrams means that potentially not every bigram is needed to reconstruct a name, e.g. David is ‘da’, ‘av’, ‘vi’, ‘id’ but guessing ‘da’, ‘vi’ and ‘id’ is enough.
My current activity focuses on further improving this accuracy by building a more robust training model. Additionally, I am investigating other identity traits that can be found in users’ typing patterns, like their passwords or native language.
If you’d like to take part in the experiment, you can add your data at https://clicka.cmp.uea.ac.uk/
Read more
- Buckley, O. and Nurse, J.R., 2019. The Language of Biometrics: Analysing Public Perceptions. Journal of Information Security and Applications, 47, pp.112–119. doi: 10.1016/j.jisa.2019.05.001
- Hodges, D. and Buckley, O., 2018. Reconstructing What You Said: Text Inference Using Smartphone Motion. IEEE Transactions on Mobile Computing, 18(4), pp.947–959. doi: 10.1109/TMC.2018.2850313
- Monrose, F. and Rubin, A., 1997. Authentication via keystroke dynamics. Proceedings of the 4th ACM conference on Computer and communications security, pp. 48–56. doi: 10.1145/266420.266434
- Messerman, A., Mustafić, T., Camtepe, S.A. and Albayrak, S., 2011. Continuous and non-intrusive identity verification in real-time environments based on free-text keystroke dynamics. International Joint Conference on Biometrics (IJCB 2011), pp.1–8. doi: 10.1016/j.jisa.2019.05.001
- Epp, C., Lippold, M. and Mandryk, R.L., 2011. Identifying emotional states using keystroke dynamics. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp.715–724. doi: 10.1145/1978942.1979046
Copyright Information
As part of CREST’s commitment to open access research, this text is available under a Creative Commons BY-NC-SA 4.0 licence. Please refer to our Copyright page for full details.
IMAGE CREDITS: Copyright ©2024 R. Stevens / CREST (CC BY-SA 4.0)